
Défini lors de l’installation du SGBD, le character set Oracle peut être modifié par la suite. Le charset est le jeu de caractères qui précise le codage utilisé pour rendre des informations lisibles. Une sorte d’alphabet pour que les logiciels sachent quel codage est utilisé par l’expéditeur du message (ASCII, ISO, UTF…).
Ce tutoriel explique comment voir le character set actuellement utilisé par un serveur Oracle et la méthode pour modifier ce charset. Cela concerne Oracle Database 12c et suivants (18c, 19c, 20c).
Voir le jeu de caractères utilisé dans Oracle
1. Ouvrir un SQL Developer ou un autre outil pour interroger un serveur Oracle.
2. Copier coller la requête suivante :
select * from v_$nls_parameters;
3. Dans les résultats, est indiqué le « NLS_CHARACTERSET » qui correspond au charset :
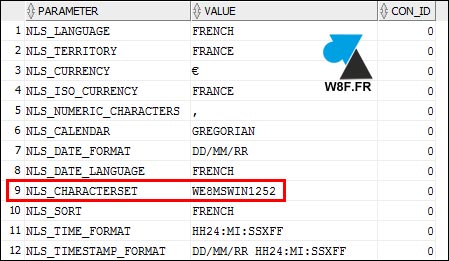
Changer le CHARACTERSET d’une base Oracle
Ce n’est pas aussi simple que ça. Si avec Oracle jusqu’à la version 9, il suffisait de faire un ALTER DATABASE CHARACTER SET AL32UTF8; ou ALTER DATABASE CHARACTER SET WE8MSWIN1252; les choses sont un peu plus compliquées depuis Oracle 10g, 11g, 12c, 18c, 19c, 20c.
On peut aussi regarder avec les outils CSSCAN et CSALTER.
Le character set forge la manière dont sont stockées les données, au niveau block. AL32UTF8 accepte tous les caractères de toutes les langues du monde, c’est le plus utilisé.
La procédure la plus propre pour changer de charset sur une base est la suivante :
- Export de la base
- Création d’une nouvelle base avec le bon character set
- Import de la base sauvegardée
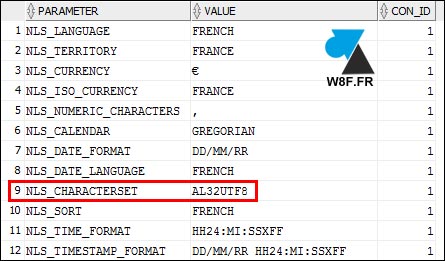
- Vérifier avec select * from v_$nls_parameters;


Hello,
Peut tu détaillé les 4 étapes :
1- Export de la base ( comment ? )
2- Création d’une nouvelle base avec le bon character set ( avec quel commande SQL ? )
3 -Import de la base sauvegardée
4 – Vérifier avec select * from v_$nls_parameters;
Merci