Si les humains utilisent différents alphabets (latin, cyrillique, arabe…), les ordinateurs aussi communiquent avec différentes manières d’écrire. Les plus anciens codages de caractères sont le code international des signaux maritimes ou encore l’alphabet Morse (1838) mais les machines utilisent plutôt le standard américain ASCII, le Standard Unicode UTF ou d’autres caractères ISO. A titre d’information, le codage UTF-8 est utilisé par plus de 90% de sites web dans le monde, faisant de lui un standard pour l’échange d’informations.
Comme tout système informatique, le serveur de bases de données Oracle Database utilise lui aussi les jeux de caractères. Ceux-ci peuvent être choisis au niveau du SGBD ou un encodage peut être appliqué à chaque base de données. Ce tutoriel explique comment voir le jeu de caractères (characterset) utilisé par un serveur Oracle Database : WE8ISO8859P15, AL32UTF8, AL16UTF16…
Ce paramètre se configure lors de l’installation de Oracle Database :
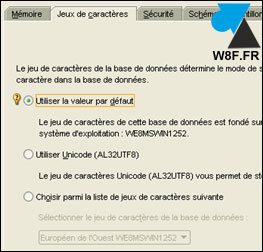
On peut d’ailleurs modifier le jeu de caractères d’une BDD lors d’un export / import mais attention à la corruption et la perte de données.
Voir le jeu de caractères utilisé dans Oracle Database
1. Ouvrir une console SQL*Plus ou un Invite de commandes Windows et se connecter à sqlplus.
2. Copier / coller la commande suivante :
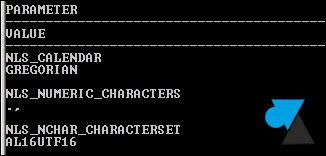
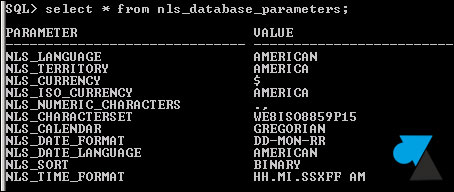
select * from nls_database_parameters;
3. Le résultat indique le Jeu de caractères utilisé à la ligne NLS_CHARACTERSET :
- AL32UTF8 pour CESU-8, un codage de caractères variante d’UTF-8 depuis Oracle 9
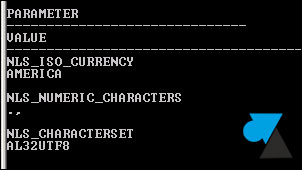
- WE8ISO8859P15 pour ISO/CEI 8859-15, le code numérique tenant sur 8 bits aux caractères de l’alphabet latin
- AL16UTF16, une variante de UTF-8